缘起:当千年古韵遇上时代回响
传承赤字:文化瑰宝的“发音鸿沟”
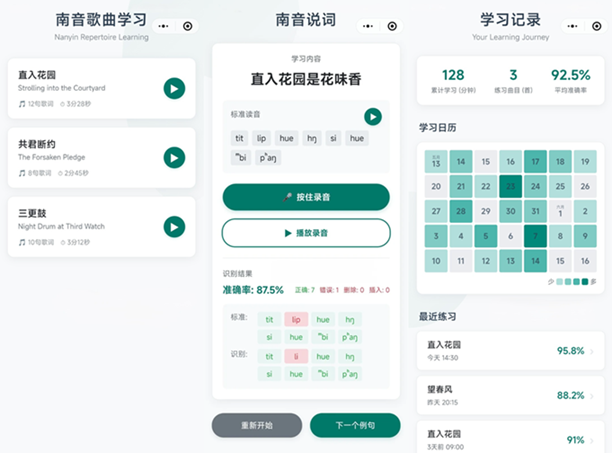
核心痛点:春晚热潮下的学习困境
南音,作为人类非物质文化遗产代表作,其传承正面临前所未有的挑战。它以独特的泉州腔为灵魂,但对于数以万计的非闽南语母语学习者而言,自学过程中缺乏实时、准确的发音反馈,极易形成难以纠正的错误发音习惯。传统的师徒口传心授模式,虽保证了传承质量,但优质师资的稀缺性,已无法满足因文化自信而激增的学习需求。

技术破局:我们的愿景与使命
解决方案:不止是工具,更是传承的阶梯
我们坚信,技术不应只是记录,更应是传承的催化剂。我们的愿景是:以AI之力,为每一位南音爱好者提供一位随身的、不知疲倦的、高度专业的发音教练。
核心破局点:不止于“听见”,更要实现“校准”。
- 发音量化:将玄妙的“腔调”拆解为可度量的音素指标。
- 实时反馈:在学习者形成错误记忆前,即时干预和纠正。
- 规模赋能:打破师资物理限制,实现标准化、个性化的教学普惠。